算法-排序
算法-排序
排序的基本概念
1.排序概念
对元素进行倒序或增序排序
默认情况下都是递增排序
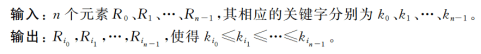
2.内排序 外排序
内排序:如果在排序过程中,整个数据表可以全部放在内存中进行处理,不需要涉及数据的内存和外存交换,这样的排序称为内排序。
例如,当数据量较小,能够一次性加载到内存中时,我们可以直接使用内存进行排序(如快速排序、插入排序等)。
外排序:如果在排序过程中,数据量太大,无法一次性放入内存中,需要通过外存(如硬盘)进行数据的交换和处理,这样的排序称为外排序。
例如,在处理超大规模的数据集(如数百万条记录)时,无法将所有数据都放入内存中,这时需要使用外排序方法,如归并排序。外排序通常会分批将数据加载到内存中,进行部分排序后再将结果写回外存,最终通过多次合并获得完整的排序结果。
内排序的例子:假设我们有一个包含 1000 个整数的数组,这些整数都可以被加载到内存中。我们可以直接使用内存中的快速排序算法对数据进行排序。
外排序的例子:假设我们有一个包含 10 亿条记录的大型文件,这些数据无法一次性加载到内存中。我们可以先将文件分成多个小文件,每个小文件都可以被加载到内存中,逐个对它们进行排序,然后将排序后的小文件依次合并,最终得到完整的排序结果。
3.内排序的分类
内排序可以分为 基于比较的排序算法 和 不基于比较的排序算法,具体如下:
- 基于比较的排序算法:
这种排序算法通过对数据中的关键字进行两两比较,来决定元素之间的顺序。
常见的基于比较的排序算法有:
- 插入排序:将元素逐个插入到已排序的部分中。
- 交换排序(如冒泡排序):通过交换无序的相邻元素,将较大(或较小)的元素逐步移动到正确位置。
- 选择排序:在每一轮中选择最小(或最大)的元素并放到相应位置。
- 归并排序:通过分治思想,将数组分为若干子数组排序后合并。
- 快速排序:通过选取一个“基准”元素,将数组分成比基准小和比基准大的两部分,递归排序。
快速排序:假设有一组数字 [3, 1, 4, 1, 5, 9],选择 3 作为基准值,将数组分为 [1, 1, 3] 和 [4, 5, 9],然后递归地对每部分排序,最后合并得到有序数组。
2.不基于比较的排序算法:
这种排序算法不直接比较关键字的大小,而是利用元素的特定属性或结构进行排序,通常用于特定的数据类型或范围。
常见的不基于比较的排序算法有:
- 基数排序:按位(如个位、十位)逐步排序,一次排序一个位数。
- 计数排序:根据元素的取值范围统计每个值的出现次数,直接构造排序结果。
- 桶排序:将数据分配到若干个“桶”中,每个桶内分别排序,最后合并各桶的数据。
基数排序:对电话号码 [123, 456, 789, 234] 进行排序,先按个位、再按十位、最后按百位排序,可以得到有序的结果 [123, 234, 456, 789]。
基于比较的排序适用于一般情况,但效率上限为 O(nlogn)O(n \log n)O(nlogn)。不基于比较的排序利用数据特性,可能实现线性时间复杂度,但通常需要额外的空间或特定数据特性。
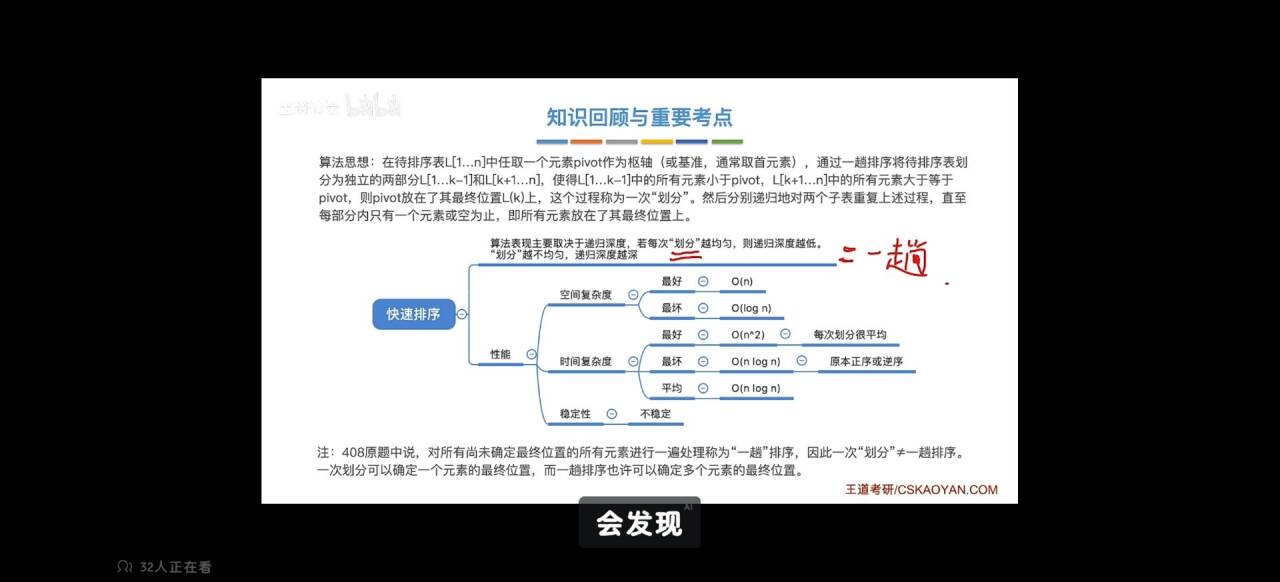
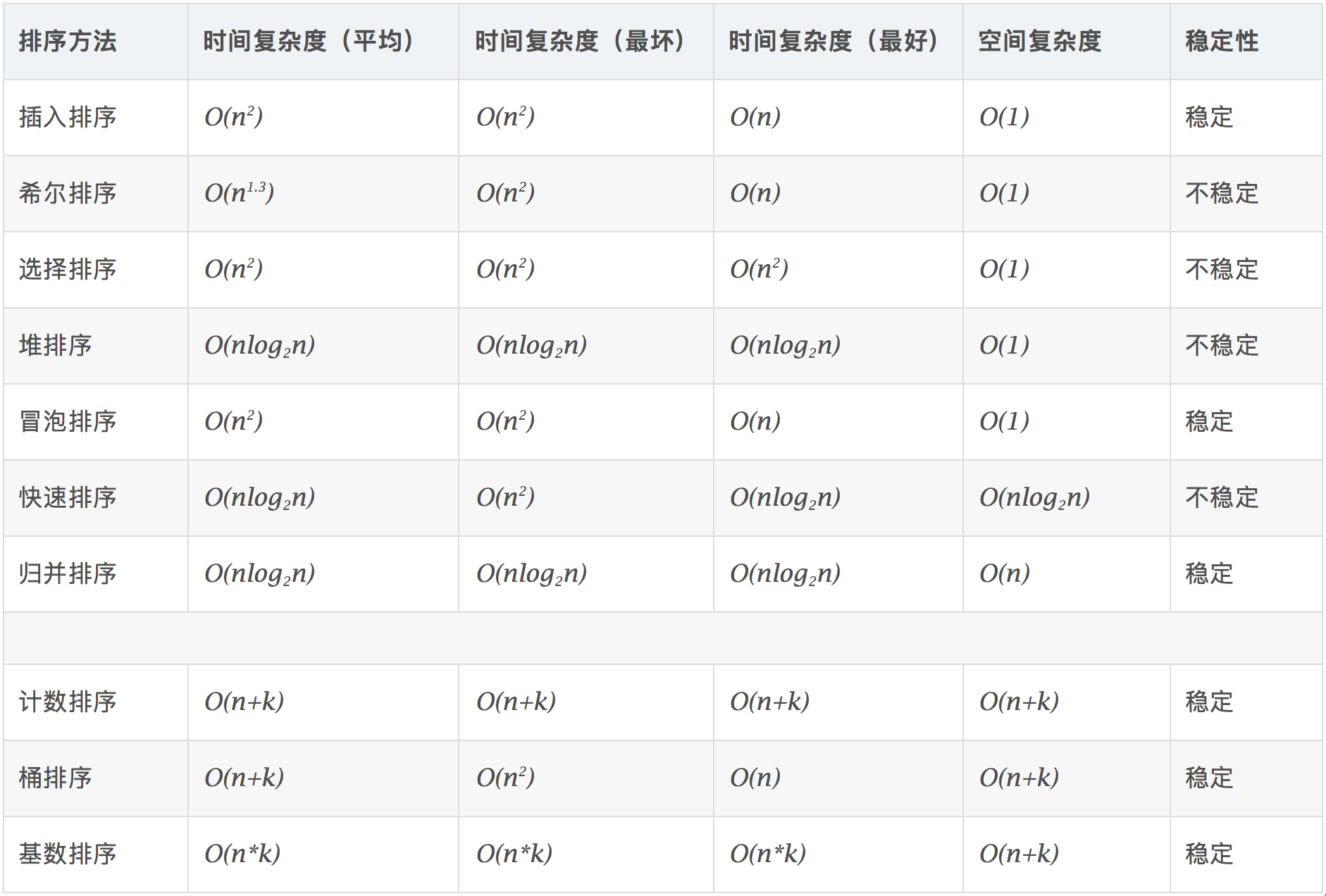
4.基于笔记的排序性能

5.内排序的稳定性
6.内排序的数据的组织

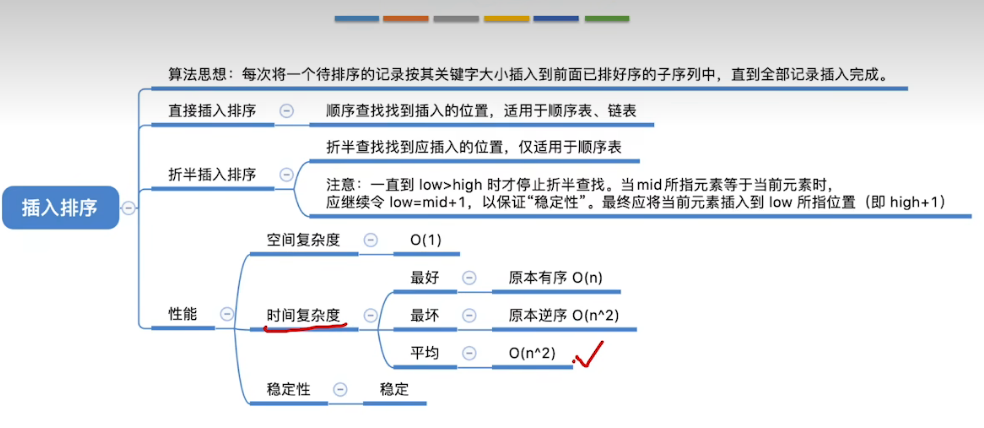
插入排序
算法思想
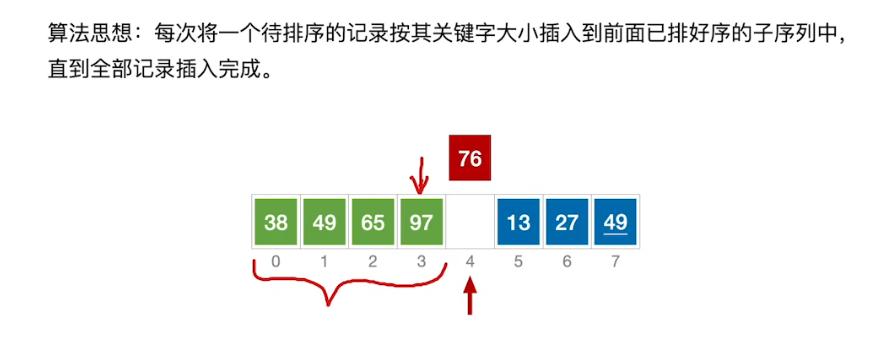
相同元素
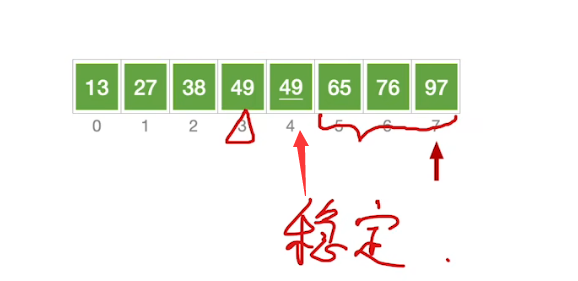
算法实现

实现2
带哨兵

复杂度

折半查找排序
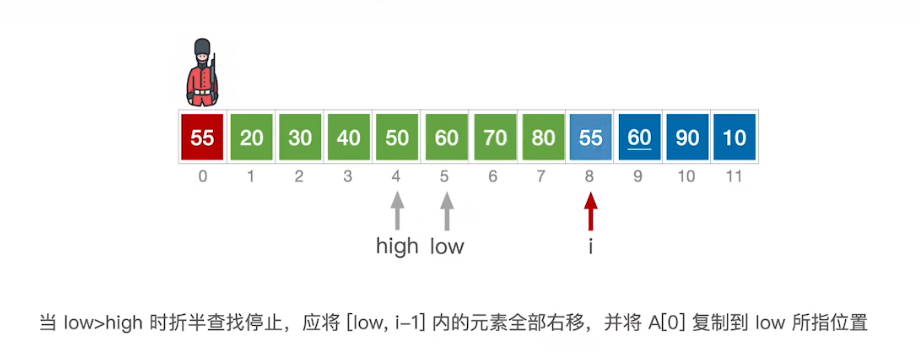
low-开头 high-末尾 折半查看落在哪个范围内
找到条件
if(high<low)
稳定性-方向不变
当前处理元素值相同
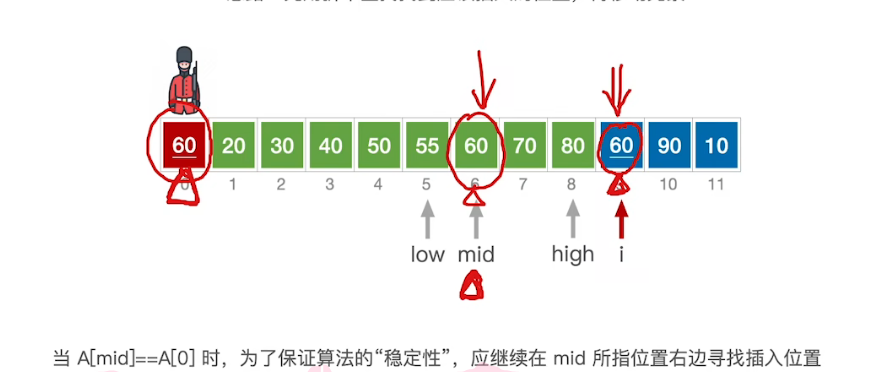
算法实现

对比
选择排序
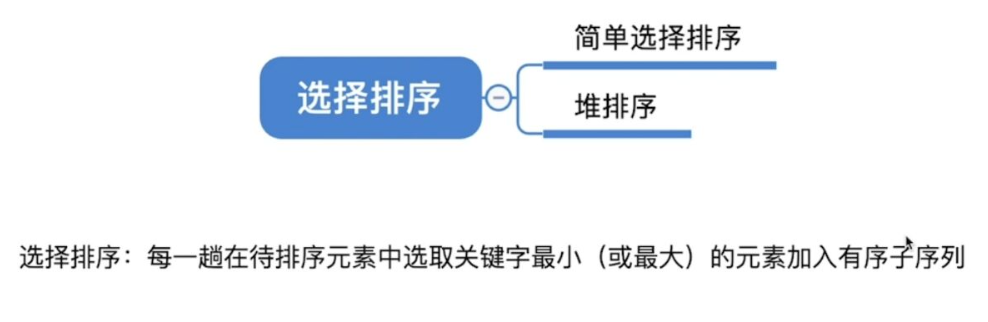
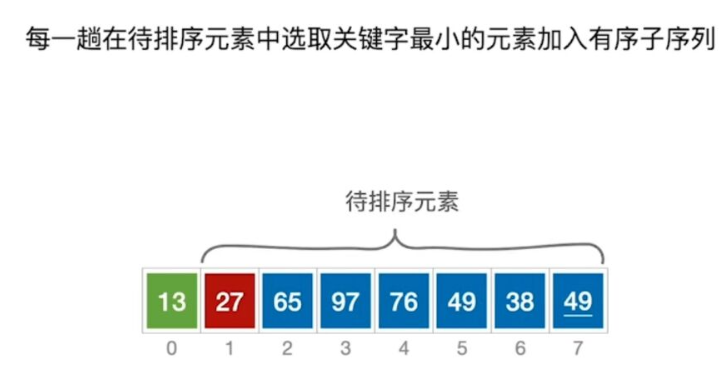
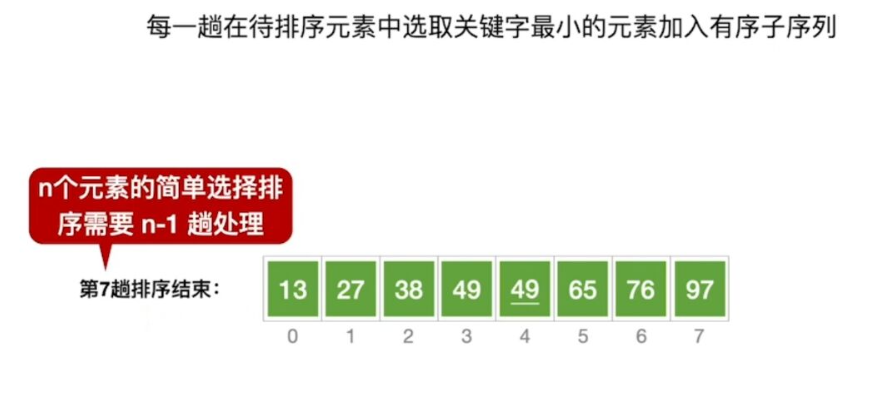
1.简单选择排序
过程
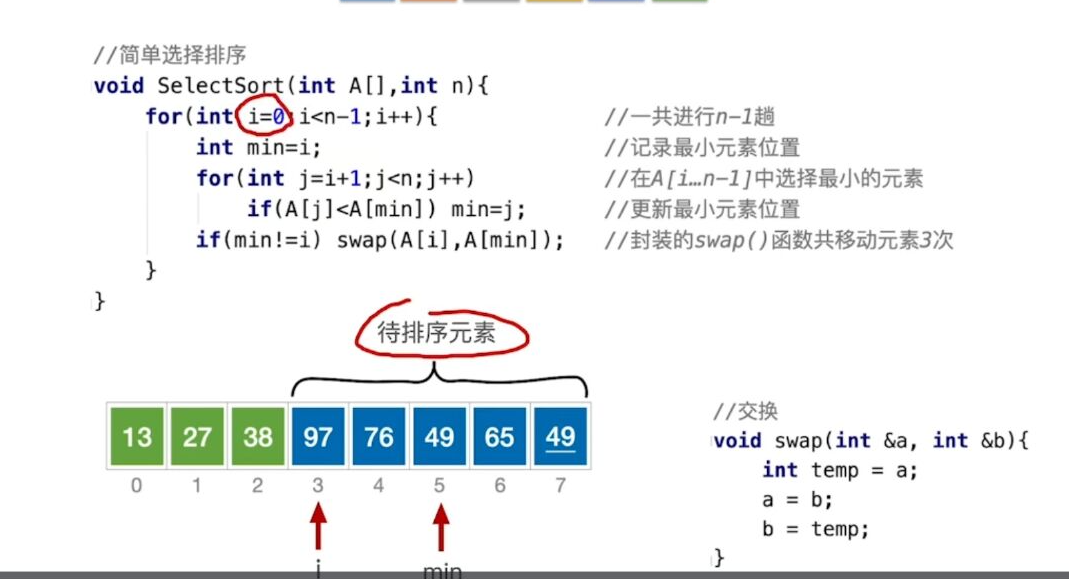
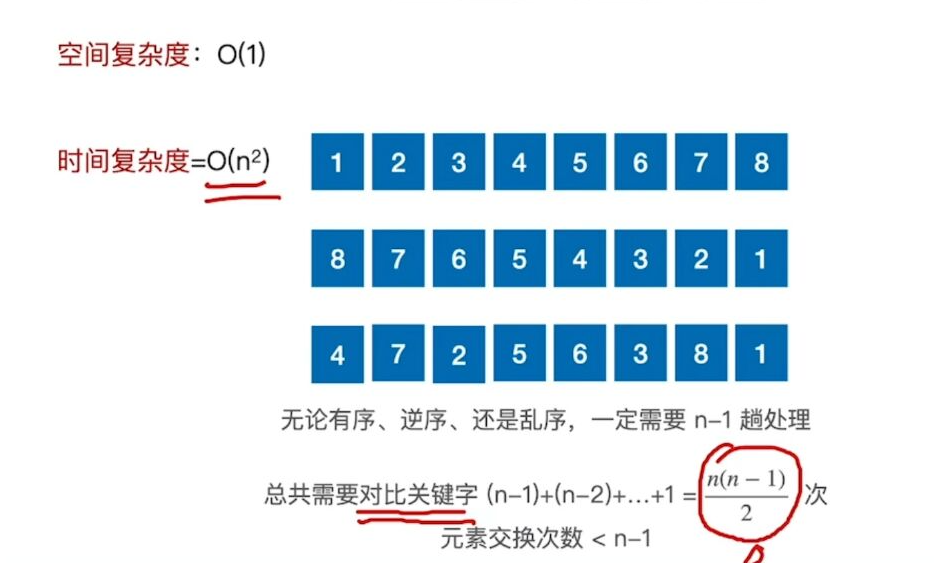
时间复杂度、


快速排序
思想
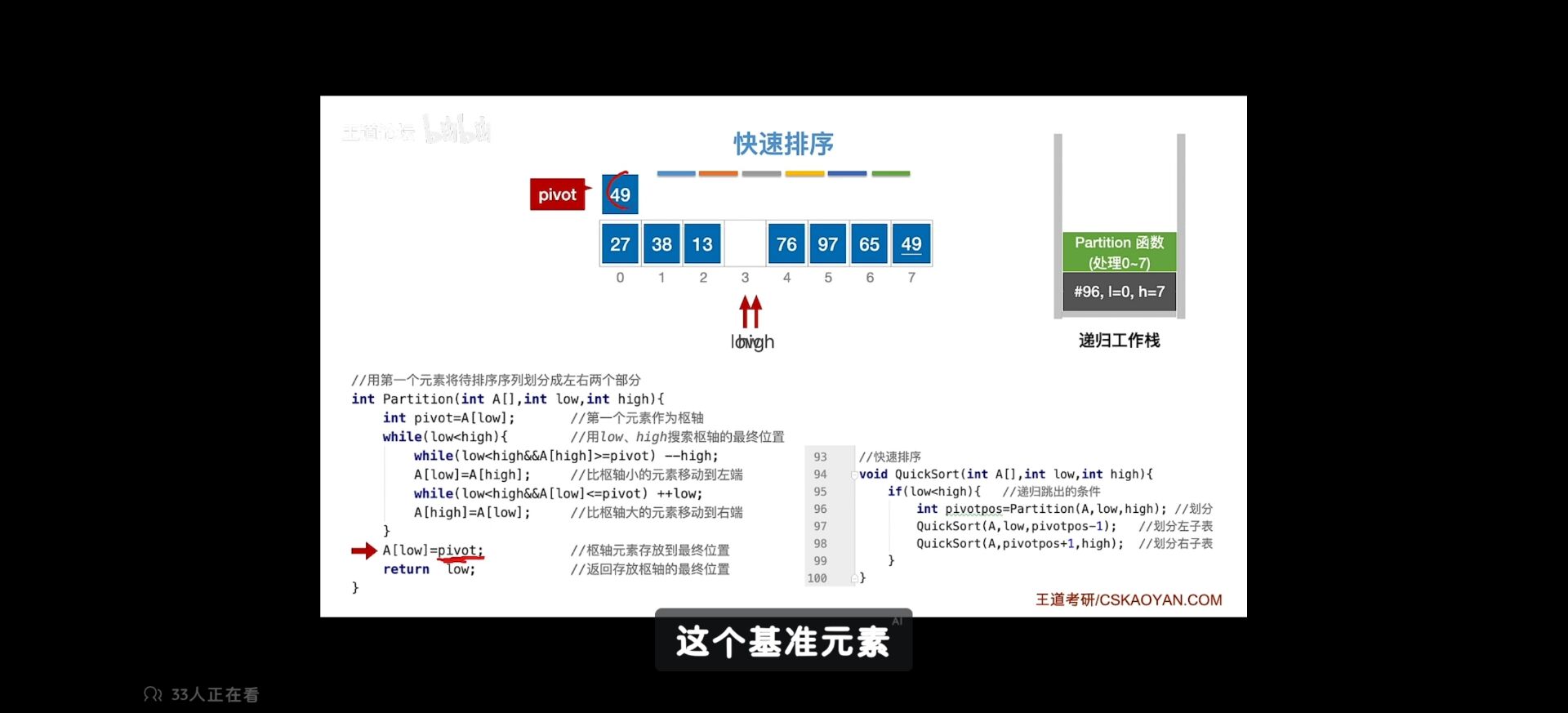
快速排序使用分治法来把一个串(list)分为两个子串(sub-lists)。具体算法描述如下:
- 从数列中挑出一个元素,称为 “基准”(pivot);
- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
过程
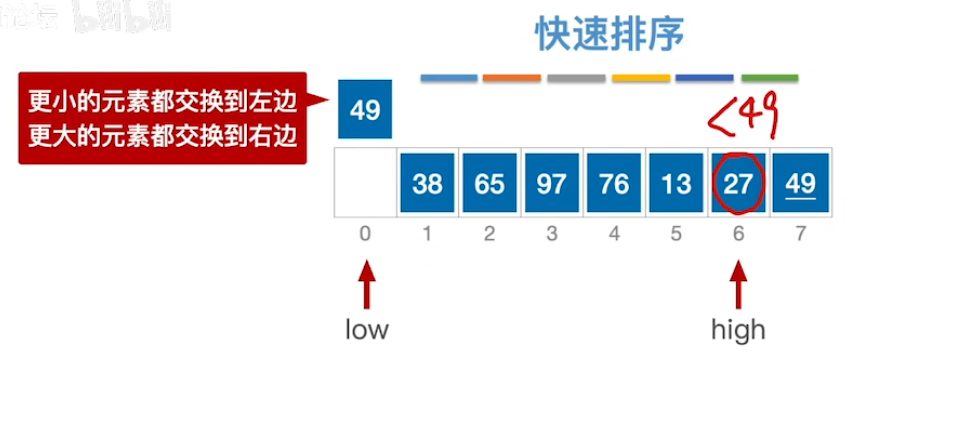
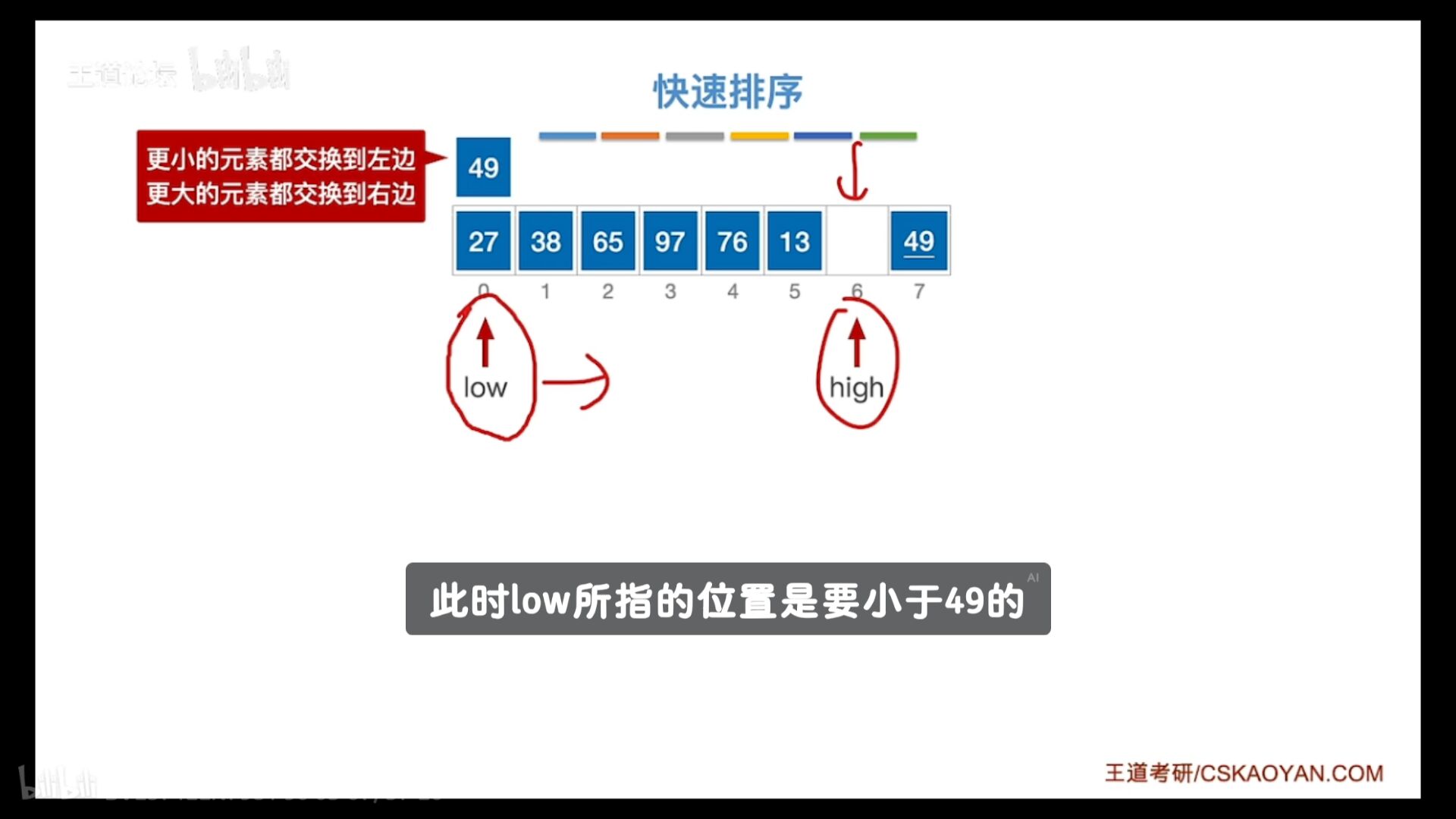
low high一直走
low左边部分都要小于49
high都要大于49
直到low=high确定-49最终位置
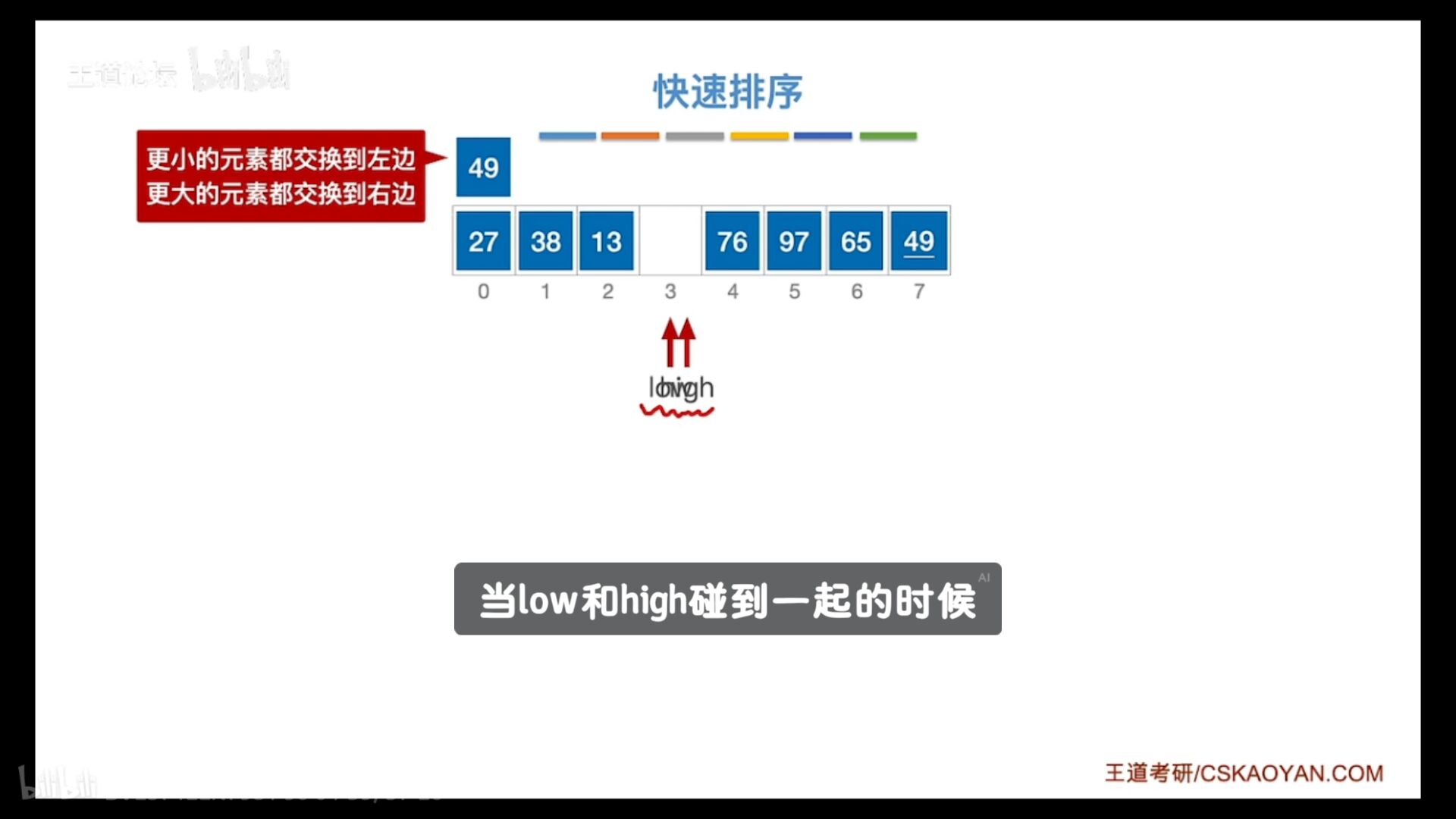
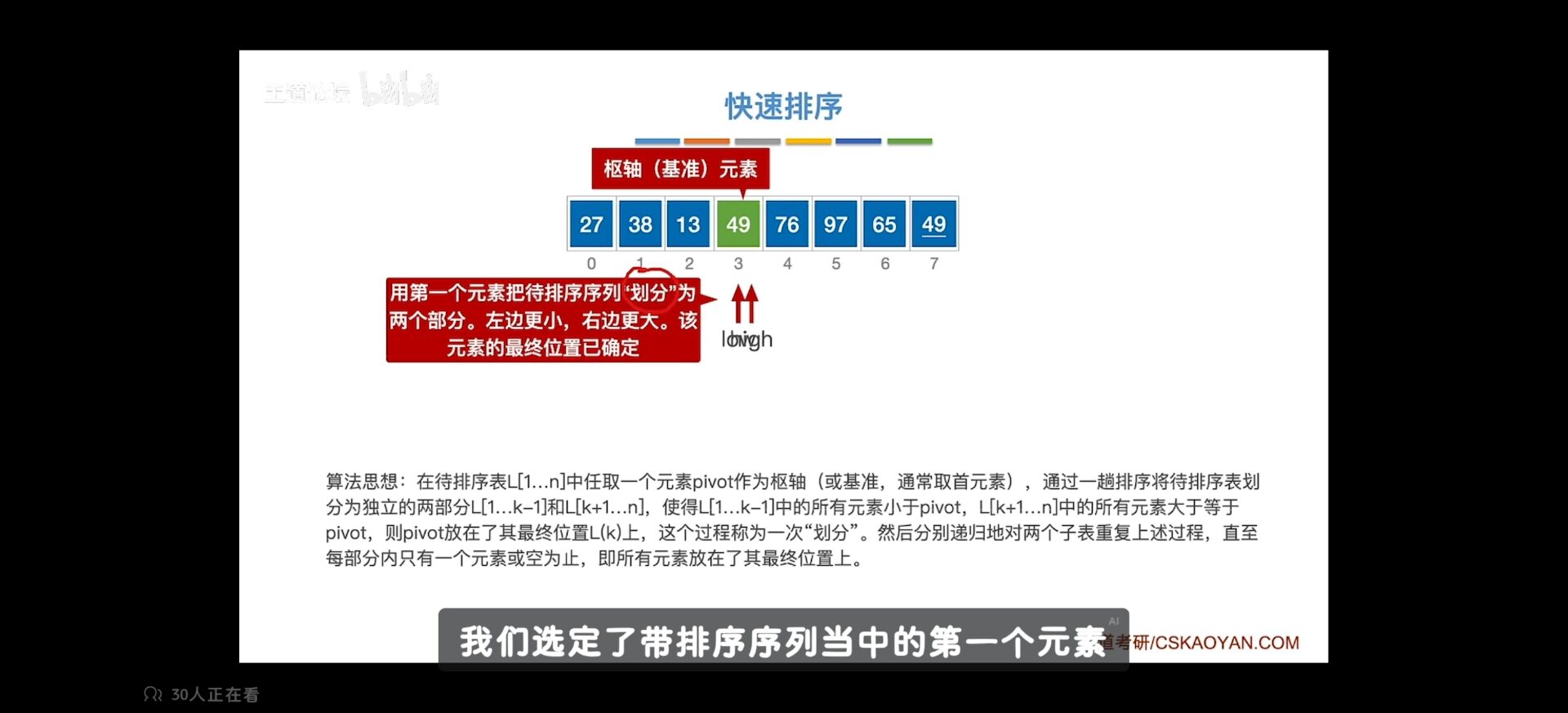
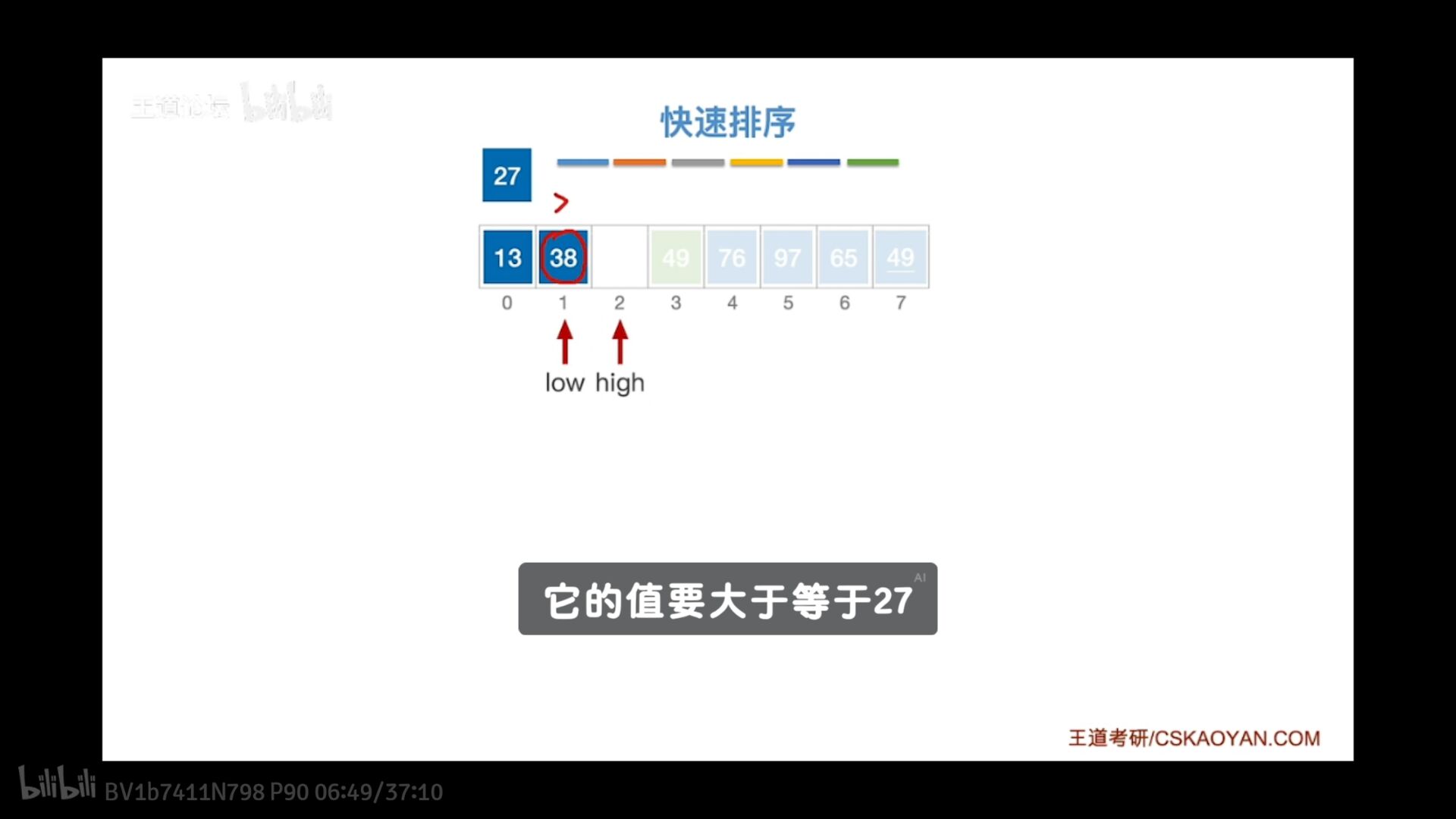
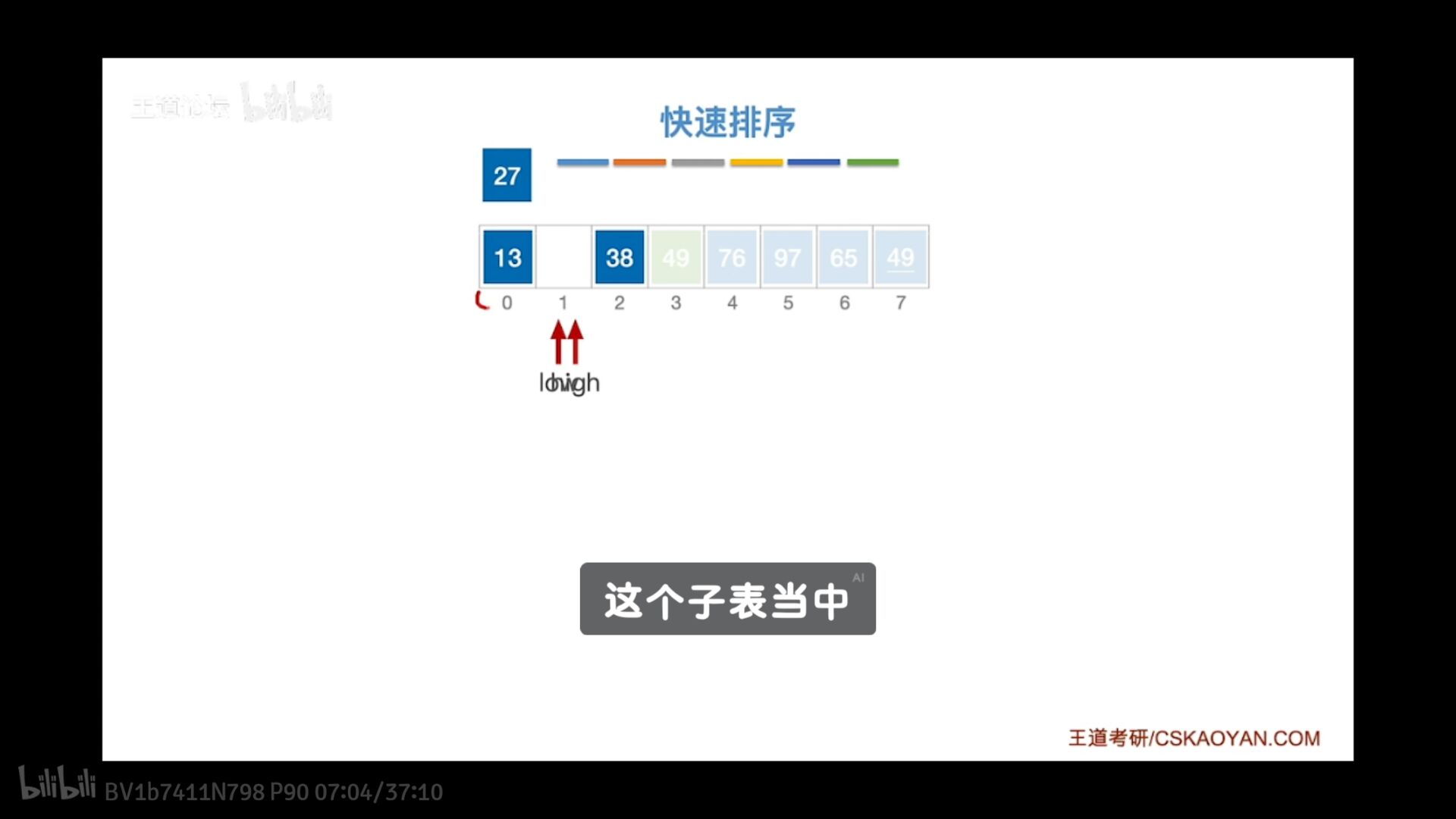
快速排序算法



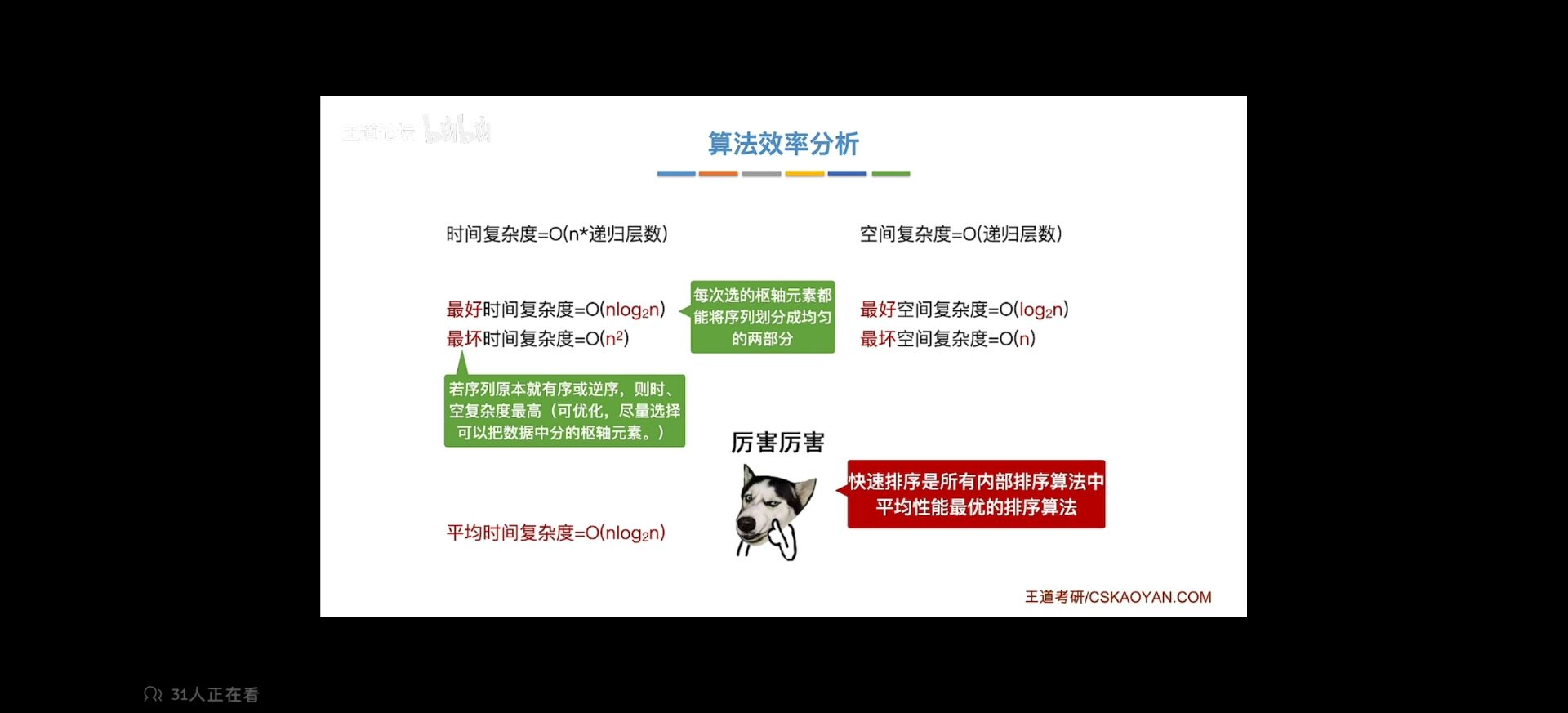
快速排序分析
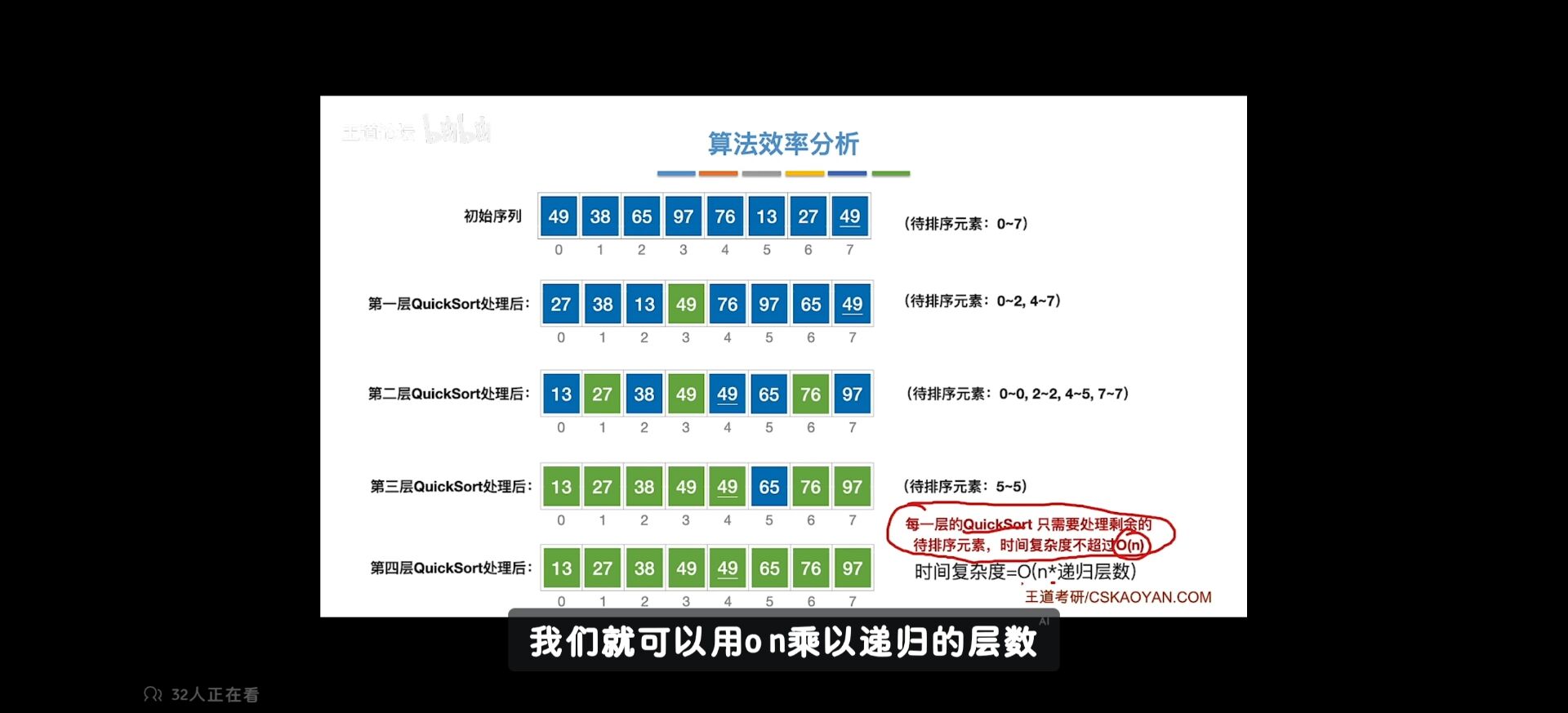
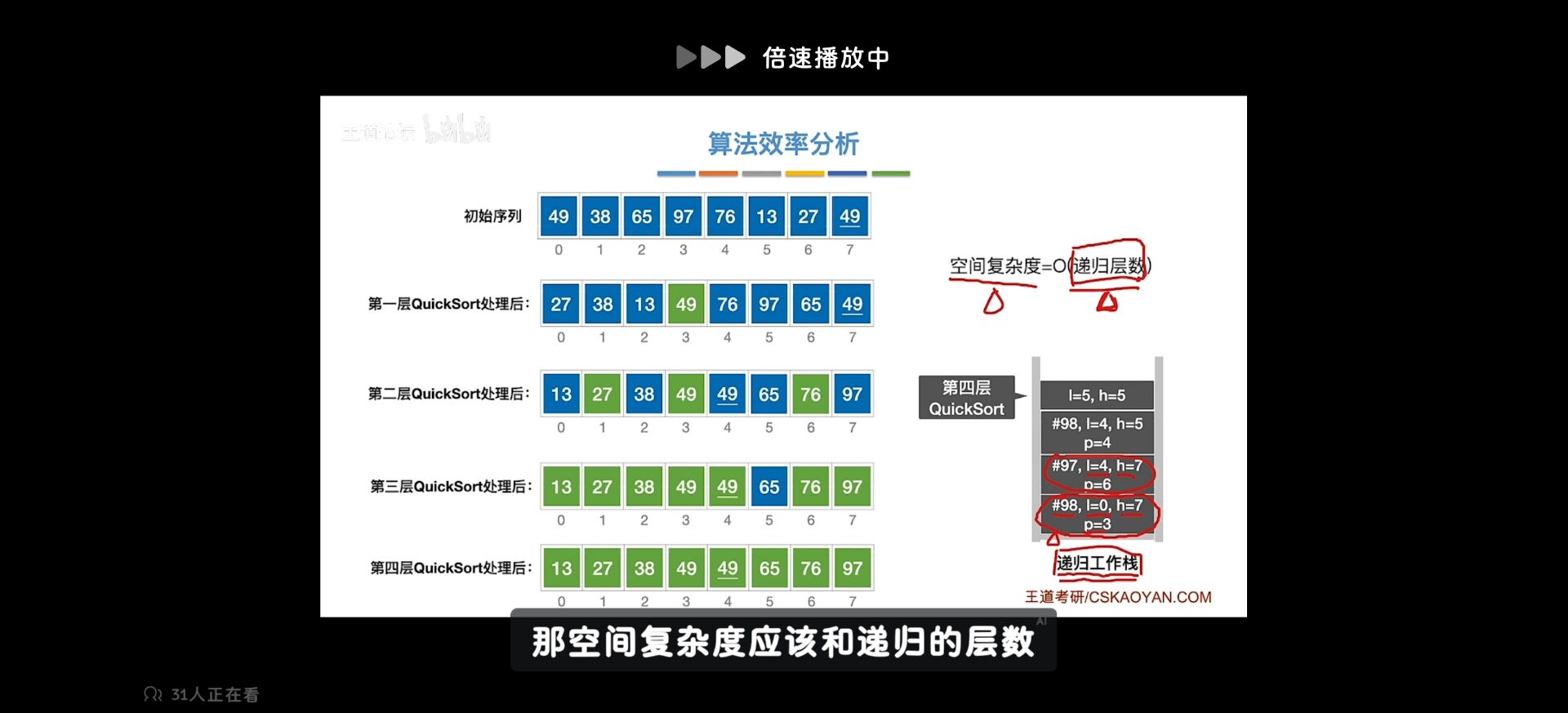
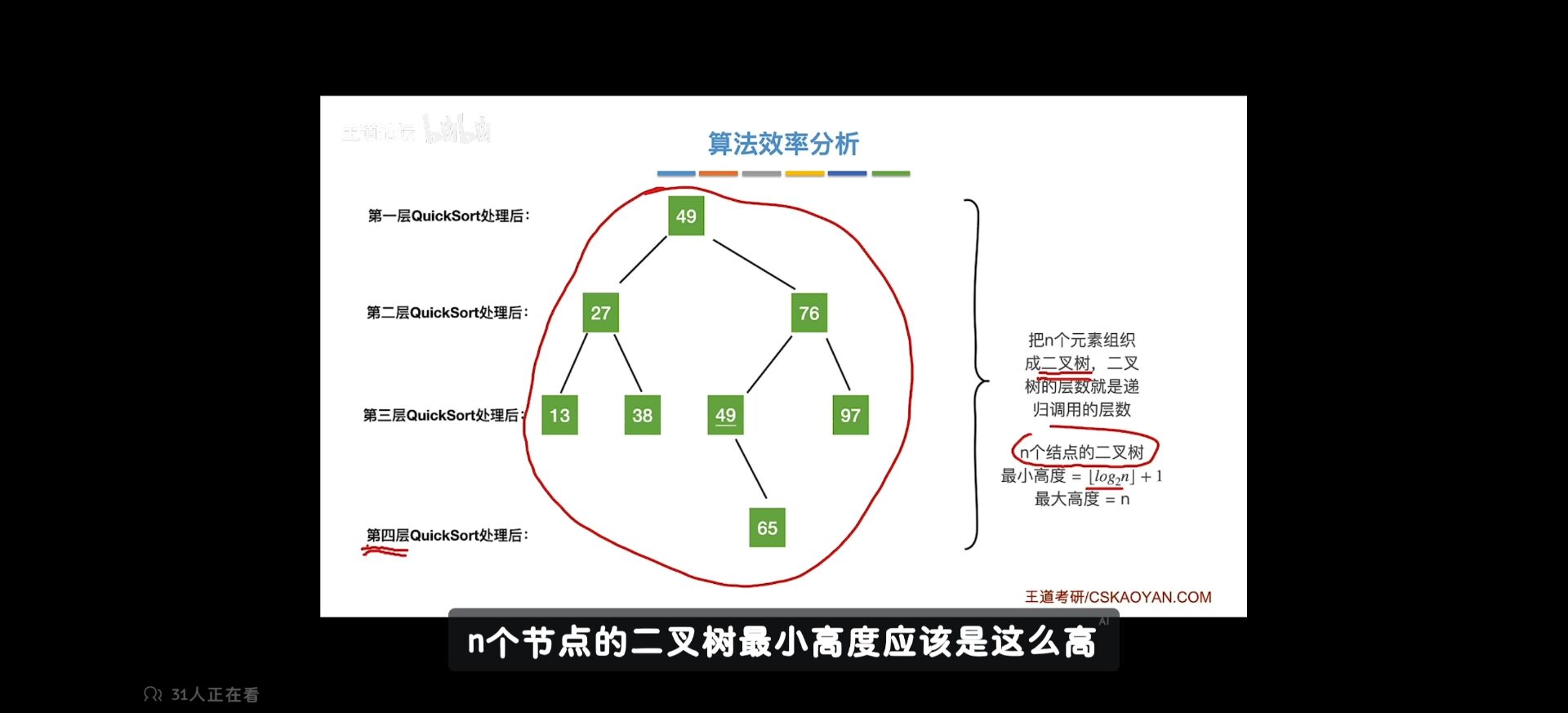

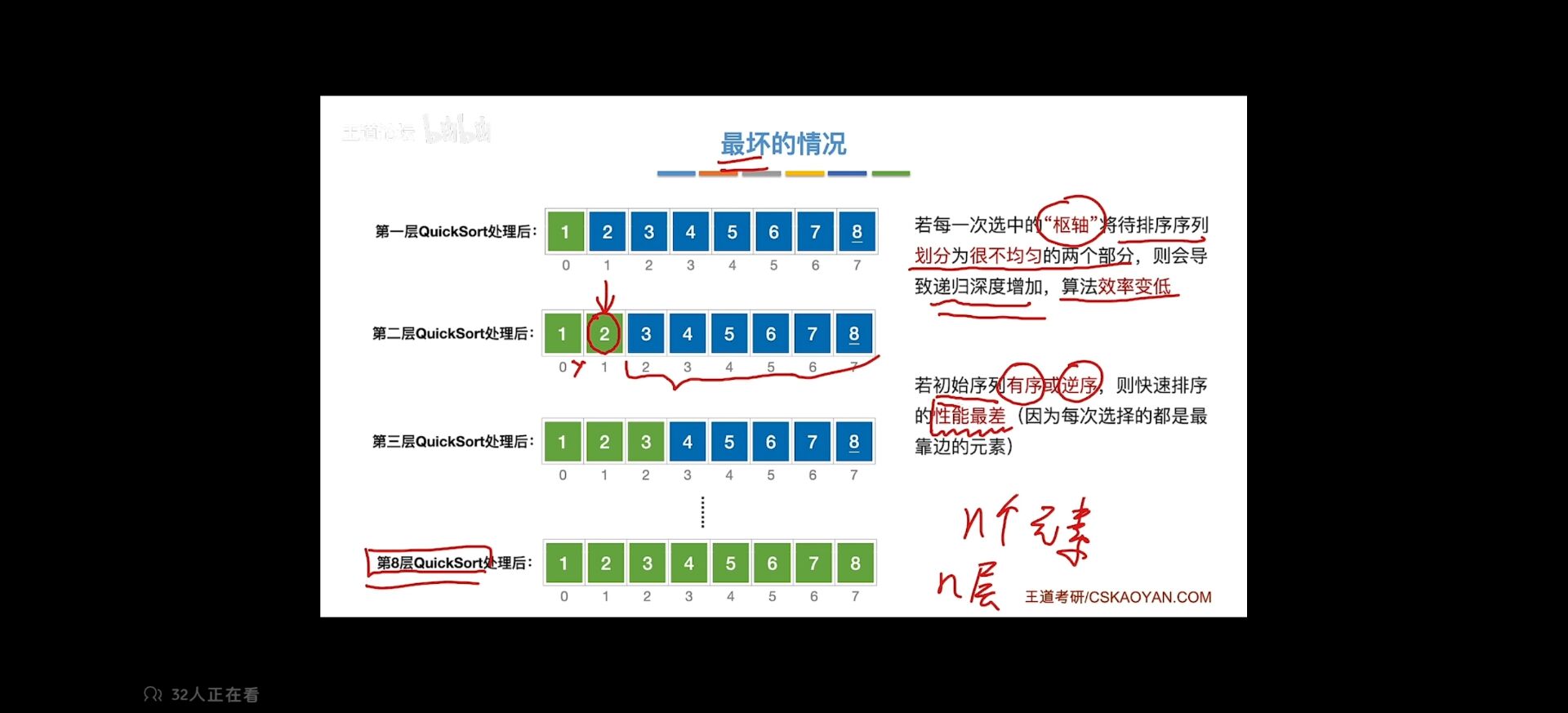
最坏 好的情况