kafka Streams
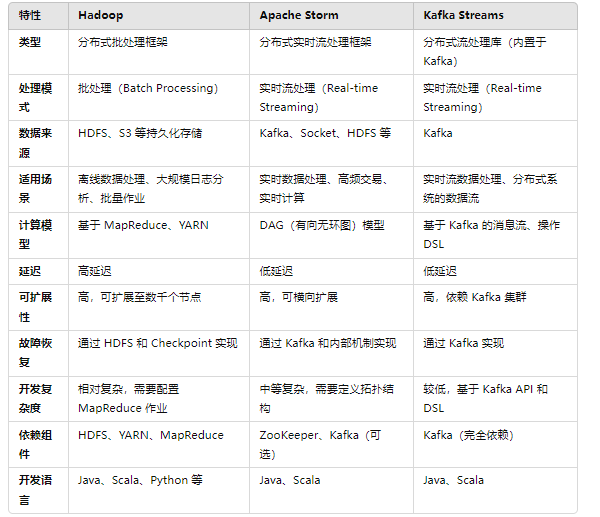
Kafka Streams:作为 Kafka 的内置流处理库,专注于处理 Kafka 中的数据流,适合需要流式处理 Kafka 消息的应用,具有简单的 API 和高效的处理能力。
1.了解kafka Streams
Kafka Stream是Apache Kafka从0.10版本引入的一个新Feature。它是提供了对存储于Kafka内的数据进行流式处理和分析的功能。
Kafka Stream的特点如下:
- Kafka Stream提供了一个非常简单而轻量的Library,它可以非常方便地嵌入任意Java应用中,也可以任意方式打包和部署
- 除了Kafka外,无任何外部依赖
- 充分利用Kafka分区机制实现水平扩展和顺序性保证
- 通过可容错的state store实现高效的状态操作(如windowed join和aggregation)
- 支持正好一次处理语义
- 提供记录级的处理能力,从而实现毫秒级的低延迟
- 支持基于事件时间的窗口操作,并且可处理晚到的数据(late arrival of records)
- 同时提供底层的处理原语Processor(类似于Storm的spout和bolt),以及高层抽象的DSL(类似于Spark的map/group/reduce)

按照时间轴堆积处理
2.Kafka Streams的关键概念
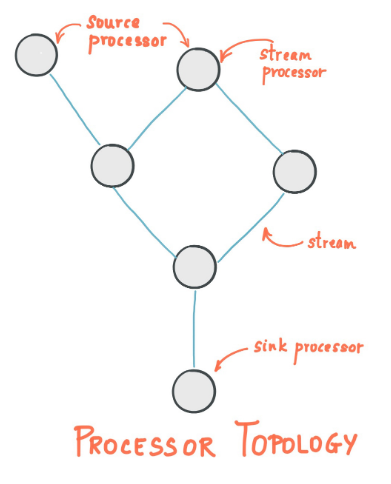
- 源处理器(Source Processor):源处理器是一个没有任何上游处理器的特殊类型的流处理器。它从一个或多个kafka主题生成输入流。通过消费这些主题的消息并将它们转发到下游处理器。-交换机
- Sink处理器:sink处理器是一个没有下游流处理器的特殊类型的流处理器。它接收上游流处理器的消息发送到一个指定的Kafka主题。-队列-与此kafka主题为消费者
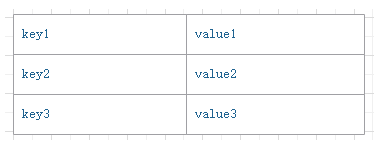
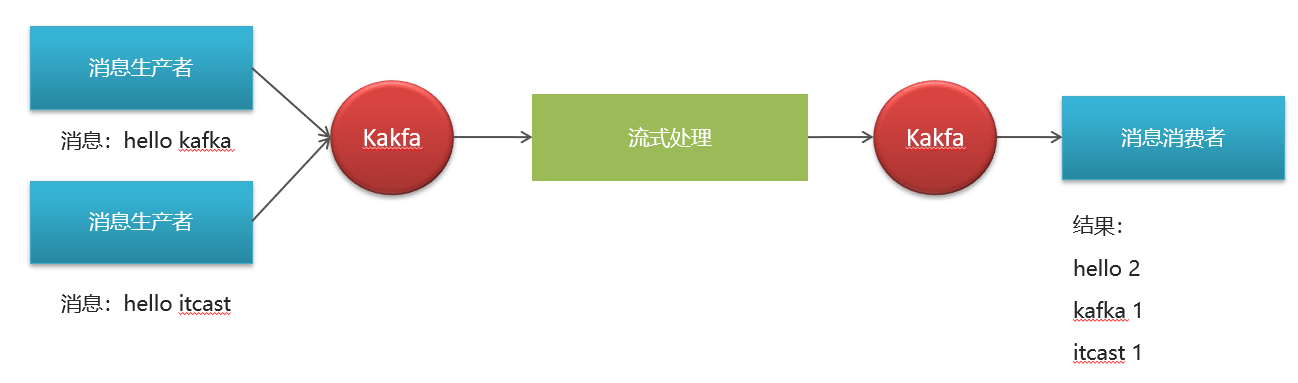
3.KStream数据结构
结构类似于map,如下图,key-value键值对
4.KStream
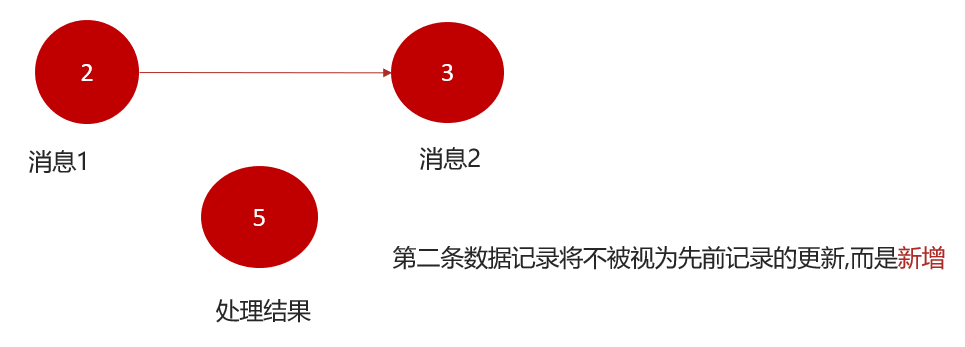
KStream 是 Kafka Streams API 中用于处理数据流的一个核心概念,代表着一个顺序且不断更新的数据集.
数据流中常记录事件,每个事件都类似于向日志中插入的新数据,而不是对之前数据的更新。
因此,每一条数据都被看作是对前一条数据的累加或增量更新。

每一条新数据都是对流中已有数据的增量,而不是对某个值的替换或更新。即使新数据和已有数据的 key 相同(如上例中的 “alice”),它们也不会覆盖,而是作为新数据插入流中。->我们可以汇总行为-算出结果集
原生代码
需求分析,求单词个数(word count)
依赖导入
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| <!-- kafkfa -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<exclusions>
<exclusion>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<exclusions>
<exclusion>
<groupId>org.apache.kafka</groupId>
<artifactId>connect-json</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
</exclusion>
</exclusions>
</dependency>
|
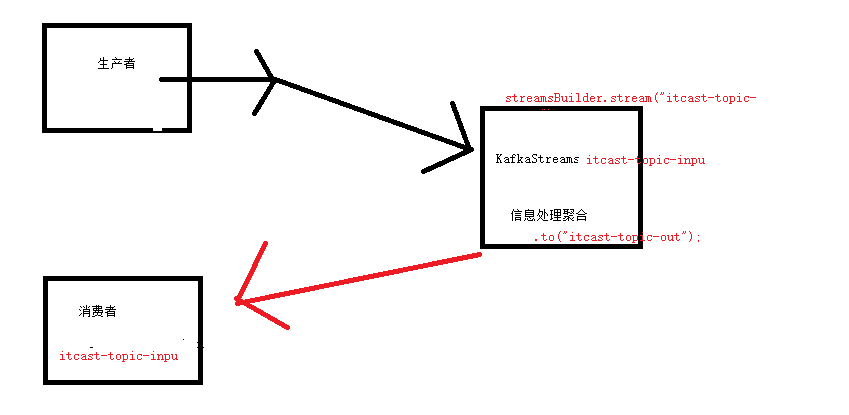
生产者发送消息:
- Kafka 生产者应用程序负责发送消息到 Kafka 集群中的主题(Topic)。在你的示例中,生产者发送消息到
itcast-topic-input 主题。
Kafka Streams 应用程序进行流处理:
- Kafka Streams 应用程序使用
StreamsBuilder 来构建流处理拓扑。
- 在你的代码中,
streamProcessor 方法定义了流处理逻辑,它从 itcast-topic-input 主题接收消息,进行处理(例如分割、聚合等),并将处理结果发送到另一个主题 itcast-topic-out。
消费者获取消息:
- Kafka 消费者应用程序连接到 Kafka 集群,并从特定主题中拉取(consume)消息。
- 在你的示例中,消费者应该订阅
itcast-topic-out 主题来获取 Kafka Streams 应用程序处理后的消息。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
public class kafka_test {
public static void main(String[] args) {
Properties prop = new Properties();
prop.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.200.130:9092");
prop.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
prop.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
prop.put(StreamsConfig.APPLICATION_ID_CONFIG,"streams-quickstart");
StreamsBuilder streamsBuilder = new StreamsBuilder();
streamProcessor(streamsBuilder);
KafkaStreams kafkaStreams = new KafkaStreams(streamsBuilder.build(),prop);
kafkaStreams.start();
}
private static void streamProcessor(StreamsBuilder streamsBuilder) {
KStream<String, String> stream = streamsBuilder.stream("itcast-topic-input");
stream.flatMapValues(new ValueMapper<String, Iterable<String>>() {
@Override
public Iterable<String> apply(String value) {
return Arrays.asList(value.split(" "));
}
})
.groupBy((key,value)->value)
.windowedBy(TimeWindows.of(Duration.ofSeconds(10)))
.count()
.toStream()
.map((key,value)->{
System.out.println("key:"+key+",vlaue:"+value);
return new KeyValue<>(key.key().toString(),value.toString());
})
.to("itcast-topic-out");
}
}
|
生产者
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
public class ProducerDemo {
public static void main(String[] args) {
Properties pro = new Properties();
pro.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"49.234.48.192:9092");
pro.put(ProducerConfig.RETRIES_CONFIG,5);
pro.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
pro.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
pro.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,"lz4");
KafkaProducer<String,String> producer = new KafkaProducer<String, String>(pro);
String[] messages = {
"hello kafka hello itcast",
"welcome to kafka streams",
"kafka is a distributed streaming platform"
};
for (String message : messages) {
ProducerRecord<String, String> record = new ProducerRecord<>("itcast-topic-input", message);
producer.send(record);
System.out.println("Sent: " + message);
}
producer.close();
}
}
|
消费者
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
public class ConsumerDemo {
public static void main(String[] args) {
Properties pro = new Properties();
pro.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"49.234.48.192:9092");
pro.put(ConsumerConfig.GROUP_ID_CONFIG,"group2");
pro.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
pro.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
pro.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(pro);
consumer.subscribe(Collections.singletonList("tbug-topic-out"));
try {
while(true) {
ConsumerRecords<String, String> messages = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> message : messages) {
System.out.print(message.key() + ":");
System.out.println(message.value());
}
}
} catch (Exception e) {
e.printStackTrace();
System.out.println("记录错误的信息:"+e);
} finally {
consumer.commitSync();
}
}
}
|
spring 集结
- JDK 8或更高版本
- Apache Kafka
- Spring Boot
- Maven
1.导入依赖
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| <dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
</dependency>
</dependencies>
|
2.在application.properties文件中添加Kafka相关的配置:
1
2
3
4
5
6
7
8
9
10
| spring.kafka.bootstrap-servers=localhost:9092
spring.kafka.consumer.auto-offset-reset=earliest///指定了消费者在读取特定主题时,如果未找到有效的 offset(比如在消费者开始读取之前主题刚刚被创建),消费者应该从哪个 offset 开始读取数据。
earliest:消费者将从每个分区的最开始处开始读取消息。
latest:消费者将从每个分区的最新记录开始读取消息。
none:消费者将拒绝读取消息,如果它找不到有效的 offset。
spring.kafka.consumer.group-id=my-group
Kafka 使用消费者组来管理一组消费者,它们共同消费一个主题的数据。每个消费者组内的消费者实例会协调彼此,以平衡负载并确保每个消息只被组内的一个消费者处理。
group-id 是用来标识一个消费者组的唯一标识符。同一个消费者组中的所有消费者将共享相同的 group-id。
|
3.创建Kafka Streams处理器
4.我们需要创建一个Kafka Streams处理器来定义我们的数据处理逻辑。可以创建一个新的类,实现Spring的KafkaStreamsDSL接口:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| @Configuration
@EnableKafkaStreams
public class KafkaStreamsProcessor implements KafkaStreamsDSL {
private static final String INPUT_TOPIC = "my-input-topic";
private static final String OUTPUT_TOPIC = "my-output-topic";
@Override
public void buildStreams(StreamsBuilder builder) {
KStream<String, String> inputTopic = builder.stream(INPUT_TOPIC);
KStream<String, String> outputTopic = inputTopic
.mapValues(value -> value.toUpperCase())
.filter((key, value) -> value.length() > 5);
outputTopic.to(OUTPUT_TOPIC);
}
}
|
在上面的代码中,我们创建了一个输入主题my-input-topic和一个输出主题my-output-topic。然后,我们使用mapValues方法将输入流中的值转换为大写,并使用filter方法过滤长度大于5的记录。最后,我们使用to方法将输出流写入输出主题。
5.我们可以在Spring Boot应用程序的主类中启动Kafka Streams处理器:
1
2
3
4
5
6
7
8
9
10
11
12
13
| @SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
KafkaStreamsProcessor kafkaStreamsProcessor =
new KafkaStreamsProcessor();
kafkaStreamsProcessor.start();
}
}
|
6.生产和消费消息
我们可以使用Kafka生产者向输入主题发送消息,并使用Kafka消费者从输出主题接收处理后的数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| @RestController
public class MessageController {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@PostMapping("/send")
public ResponseEntity<String> sendMessage(@RequestBody String message) {
kafkaTemplate.send("my-input-topic", message);
return ResponseEntity.ok("Message sent successfully");
}
@GetMapping("/receive")
public ResponseEntity<List<String>> receiveMessages() {
List<String> messages = // 从输出主题读取消息
return ResponseEntity.ok(messages);
}
}
|
使用
计算音乐热点值
1.导出依赖
2.编写输出类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| @Data
@Api(value = "消息发送增量")
public class UpdateArticleMess {
private String musicid;
private Integer add;
private UpdateArticleType type;
public enum UpdateArticleType {
COMMENT,
LIKE,
VIEWS;
}
}
|
3.编写发送消息
1
2
3
4
5
6
7
8
9
10
11
12
| public class HotArticleConstants {
public static final String HOT_ARTICLE_CONSUMER_QUEUE = "hot_article_consumer_queue";
public static final String HOT_ARTICLE_PRODUCER_QUEUE = "hot_article_producer_queue";
public static final String HOT_ARTICLE_AGGREGATION_QUEUE = "hot_article_aggregation_queue";
}
|
发送消息到聚合处理
1
2
3
4
5
6
7
8
| String mucisId = String.valueOf(redisTemplate.opsForHash().increment("onlineMusic:" + MusicId, OnlineMusicField.PLAY_COUNT.getFieldCode(), 1));
UpdateArticleMess mess=new UpdateArticleMess();
mess.setMusicid(MusicId);
mess.setAdd(1);
mess.setType(UpdateArticleMess.UpdateArticleType.VIEWS);
kmsTemplate.send( HotArticleConstants.HOT_ARTICLE_AGGREGATION_QUEUE,mess);
|
4..定义消息封装类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| @Data
public class ArticleVisitStreamMess {
private String muicid ;
private int view;
private int comment;
private int like;
}
|
5.编写数据聚合处理 **
ps:感谢ai大老人
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
| @Configuration
@Slf4j
public class HotArticleStreamHandler {
@Bean
public KStream<String,String> kStream(StreamsBuilder streamsBuilder) {
KStream<String, String> stream = streamsBuilder.stream(HotArticleConstants.HOT_ARTICLE_AGGREGATION_QUEUE);
stream.map((key,value)->
{
UpdateArticleMess mess= JSON.parseObject(value,UpdateArticleMess.class);
String musicid = mess.getMusicid();
String typeAndAdd =mess.getType().name()+mess.getAdd();
return new KeyValue<>(musicid, typeAndAdd);
}
).groupBy((key,value)->key)
.windowedBy(TimeWindows.of(Duration.ofSeconds(10)))
.aggregate(new Initializer<String>()
{
@Override
public String apply() {
return "view:0,comment:0,like:0";
}
},new Aggregator<String,String,String>()
{
@Override
public String apply(String key, String value, String aggValue) {
if(StringUtils.isBlank(value))
{
return aggValue;
}
String[] aggAry = aggValue.split(",");
int com=0,lik=0,vie=0;
for (String item : aggAry) {
if(item.startsWith("comment"))
{
com=Integer.parseInt(item.split(":")[1]);
}else if(item.startsWith("like"))
{
lik=Integer.parseInt(item.split(":")[1]);
}else if(item.startsWith("view"))
{
vie=Integer.parseInt(item.split(":")[1]);
}
}
String[] valAry = value.split(":");
if(valAry[0].equals("view"))
{
vie+=Integer.parseInt(valAry[1]);
}else if(valAry[0].equals("comment"))
{
com+=Integer.parseInt(valAry[1]);
}else if(valAry[0].equals("like"))
{
lik+=Integer.parseInt(valAry[1]);
}
String formatStr = String.format(",COMMENT:%d,LIKES:%d,VIEWS:%d", com, lik, vie);
System.out.println("文章的id:"+key);
System.out.println("当前时间窗口内的消息处理结果:"+formatStr);
return formatStr;
}
}, Materialized.as("hot-article-stream-aggregation-store"))
.toStream().map((key,value)->{
return new KeyValue<>(key.key().toString(),formatObj(key.key().toString(),value));
}).to(HotArticleConstants.HOT_ARTICLE_PRODUCER_QUEUE);
return stream;
}
private Object formatObj(String mucid, String value) {
ArticleVisitStreamMess mess = new ArticleVisitStreamMess();
mess.setMuicid(mucid);
String[] valAry = value.split(",");
for (String val : valAry) {
String[] split = val.split(":");
switch (UpdateArticleMess.UpdateArticleType.valueOf(split[0])){
case COMMENT:
mess.setComment(Integer.parseInt(split[1]));
break;
case LIKE:
mess.setLike(Integer.parseInt(split[1]));
break;
case VIEWS:
mess.setView(Integer.parseInt(split[1]));
break;
}
}
log.info("聚合消息处理之后的结果为:{}",JSON.toJSONString(mess));
return JSON.toJSONString(mess);
}
}
|
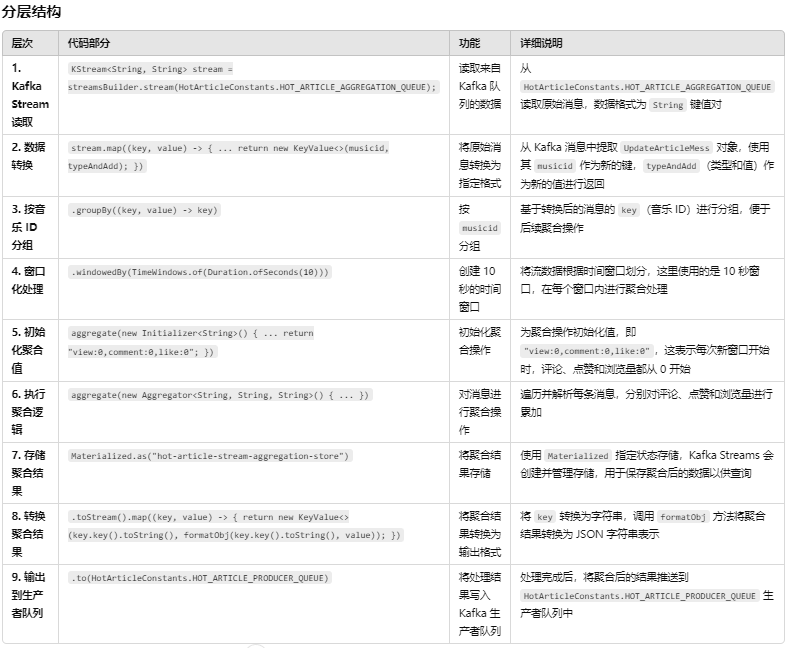
分层聚合图片
该代码的核心是流处理的三个阶段:
- 读取来自 Kafka 队列的数据流。
- 对数据进行映射、分组和聚合处理。
- 将聚合后的结果输出到另一个 Kafka 队列。
6.定义监听者
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| @Component
@Slf4j
public class ArticleIncrHandleListener {
@Autowired
RedisTemplate redisTemplate;
@KafkaListener(topics = HotArticleConstants.HOT_ARTICLE_CONSUMER_QUEUE)
public void handle(String message) {
ArticleVisitStreamMess mess= JSON.parseObject(message, ArticleVisitStreamMess.class);
savemess(mess);
log.info("收到消息:{}", message);
}
private void savemess(ArticleVisitStreamMess mess) {
}
}
|
ps:集体逻辑完了